library(here) # manage file pathslibrary(socviz) # data and some useful functionslibrary(tidyverse) # your friend and minelibrary(tidycensus) # Tidily interact with the US Censuslibrary(maps) # Some basic maps
Attaching package: 'maps'
The following object is masked from 'package:purrr':
map
library(sf) # Make maps in ggplot
Linking to GEOS 3.11.0, GDAL 3.5.3, PROJ 9.1.0; sf_use_s2() is TRUE
library(tigris) # Talk to the Census's TIGER data
To enable caching of data, set `options(tigris_use_cache = TRUE)`
in your R script or .Rprofile.
library(ggforce) # Useful enhancements to ggplot
Proper Maps with Simple Features
geom_polygon() is limiting
It’s very useful to have the intuition that, when drawing maps, we’re just working with tables of x and y coordinates, and shapes represent quantities in our data, in a way that’s essentially the same as any other geom. This makes it worth getting comfortable with what geom_polygon() and coord_map() are doing. But the business of having very large map tables and manually specifying projections is inefficient.
In addition, sometimes our data really is properly spatial, at which point we need a more rigorous and consistent way of specifying those elements. There’s a whole world of Geodesic standards and methods devoted to specifying these things for GIS applications. R is not a dedicated GIS, but we can take advantage of these tools.
Enter simple features, the sf package, and geom_sf()
The Simple Features package
When we load sf it creates a way to use several standard GIS concepts and tools, such as the GEOS library for computational geometry, the PROJ software that transforms spatial coordinates from one reference system to another, as in map projections, and the Simple Features standard for specifying the elements of spatial attributes.
library(sf)
Linking to GEOS 3.11.0, GDAL 3.5.3, PROJ 9.1.0; sf_use_s2() is TRUE
Let’s see the main upshot for us.
What’s a Feature?
A feature is a thing or object in the real world: a building, a tree, a field, a county.
Like real objects, features are often made of other objects.
“A set of features can form a single feature: A forest stand can be a feature, a forest can be a feature, a city can be a feature. A satellite image pixel can be a feature, a complete image can be a feature too.”
Features have a geometry describing where on Earth the feature is located, and they have attributes, which describe other properties.
Features have Dimensions
All geometries are composed of points. Points are coordinates in a 2-, 3- or 4-dimensional space. All points in a geometry have the same dimensionality. In addition to X and Y coordinates, there are two optional additional dimensions:
a Z coordinate, denoting altitude
an M coordinate (rarely used), denoting some measure that is associated with the point, rather than with the feature as a whole (in which case it would be a feature attribute); examples could be time of measurement, or measurement error of the coordinates
Features have Dimensions
T. Two-dimensional points refer to x and y, easting and northing, or longitude and latitude, we refer to them as XY 2. Three-dimensional points as XYZ 3. Three-dimensional points as XYM 4. Four-dimensional points as XYZM (the third axis is Z, fourth M)
The most common kinds
type
description
POINT
zero-dimensional geometry containing a single point
LINESTRING
sequence of points connected by straight, non-self intersecting line pieces; one-dimensional geometry
POLYGON
geometry with a positive area (two-dimensional); sequence of points form a closed, non-self intersecting ring; the first ring denotes the exterior ring, zero or more subsequent rings denote holes in this exterior ring
MULTIPOINT
set of points; a MULTIPOINT is simple if no two Points in the MULTIPOINT are equal
MULTILINESTRING
set of linestrings
MULTIPOLYGON
set of polygons
GEOMETRYCOLLECTION
set of geometries of any type except GEOMETRYCOLLECTION
What they look like
Coordinate reference system
Coordinates can only be placed on the Earth’s surface when their coordinate reference system (CRS) is known; this may be a spheroid CRS such as WGS84, a projected, two-dimensional (Cartesian) CRS such as a UTM zone or Web Mercator, or a CRS in three-dimensions, or including time.
Example: North Carolina
Conveniently, the example in the SF package is our beloved state.
We can perform spatial operations much, much more easily. They’re just like any other calculationg or grouping action.
What Simple Features buy us
## Make a variable picking out five counties near where I livenc <- nc |>mutate(near_me =case_when(NAME %in%c("Orange", "Durham", "Wake", "Chatham", "Alamance") ~"Near Me", TRUE~"Far Away"))## What we just didnc |>count(near_me)
Simple feature collection with 2 features and 2 fields
Geometry type: GEOMETRY
Dimension: XY
Bounding box: xmin: -84.32385 ymin: 33.88199 xmax: -75.45698 ymax: 36.58965
Geodetic CRS: NAD27
near_me n geometry
1 Far Away 95 MULTIPOLYGON (((-76.46926 3...
2 Near Me 5 POLYGON ((-79.54099 35.8369...
## These are all still county polygons. But now ...nc_merged <- nc |>group_by(near_me) |>summarize(mean_b =mean(BIR74), sum_sid =sum(SID74))nc_merged
Simple feature collection with 2 features and 3 fields
Geometry type: GEOMETRY
Dimension: XY
Bounding box: xmin: -84.32385 ymin: 33.88199 xmax: -75.45698 ymax: 36.58965
Geodetic CRS: NAD27
# A tibble: 2 × 4
near_me mean_b sum_sid geometry
<chr> <dbl> <dbl> <GEOMETRY [°]>
1 Far Away 3137. 616 MULTIPOLYGON (((-76.46926 34.69328, -76.2877 34.87701…
2 Near Me 6387. 51 POLYGON ((-79.54099 35.83699, -79.55536 35.51305, -79…
What Simple Features buy us
## Now we only have two polygonsnc_merged |>ggplot() +geom_sf(mapping =aes(fill = near_me)) +scale_fill_viridis_d() +theme(legend.position ="bottom") +labs(fill ="Near or Far?")
More sf goodies
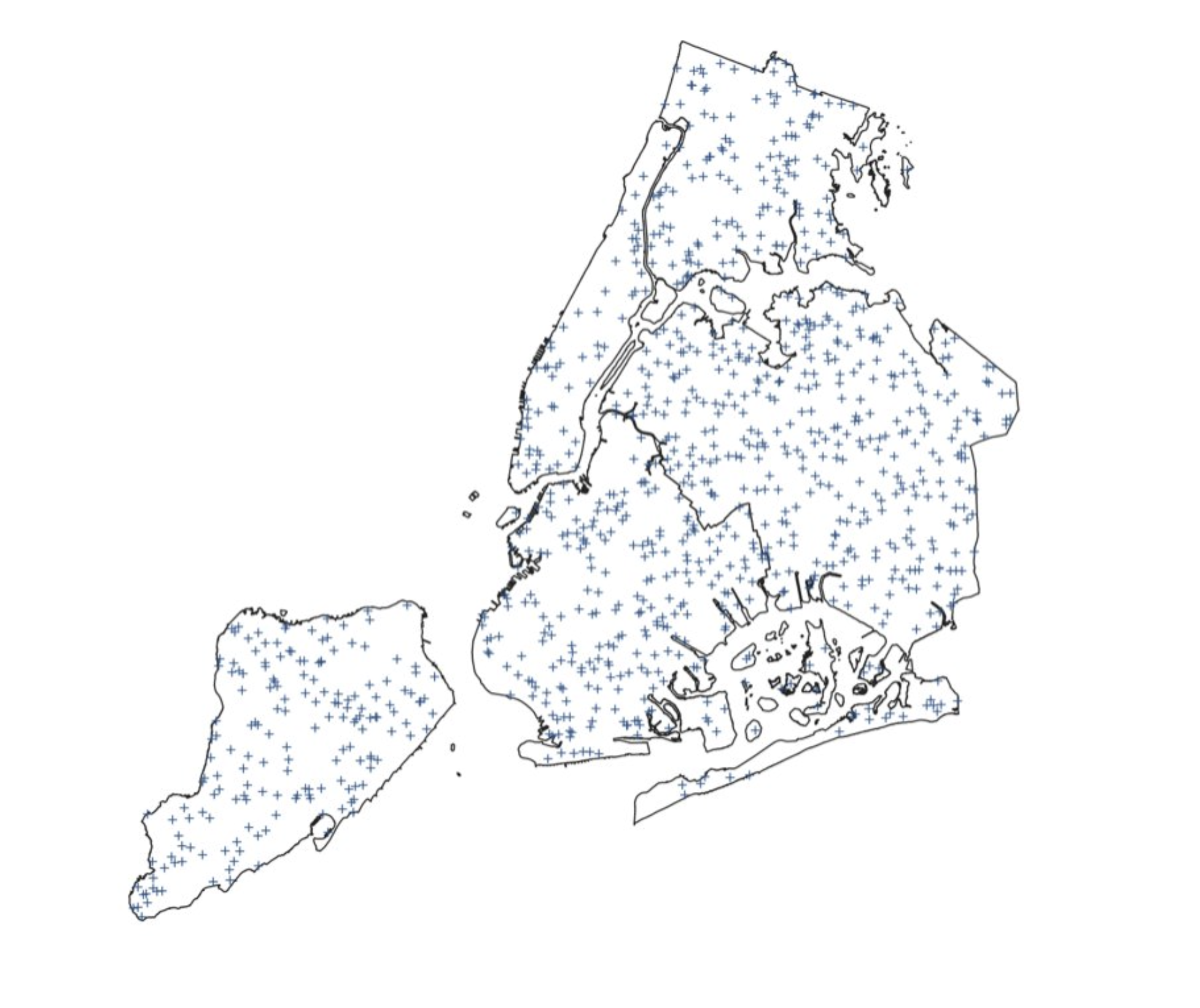
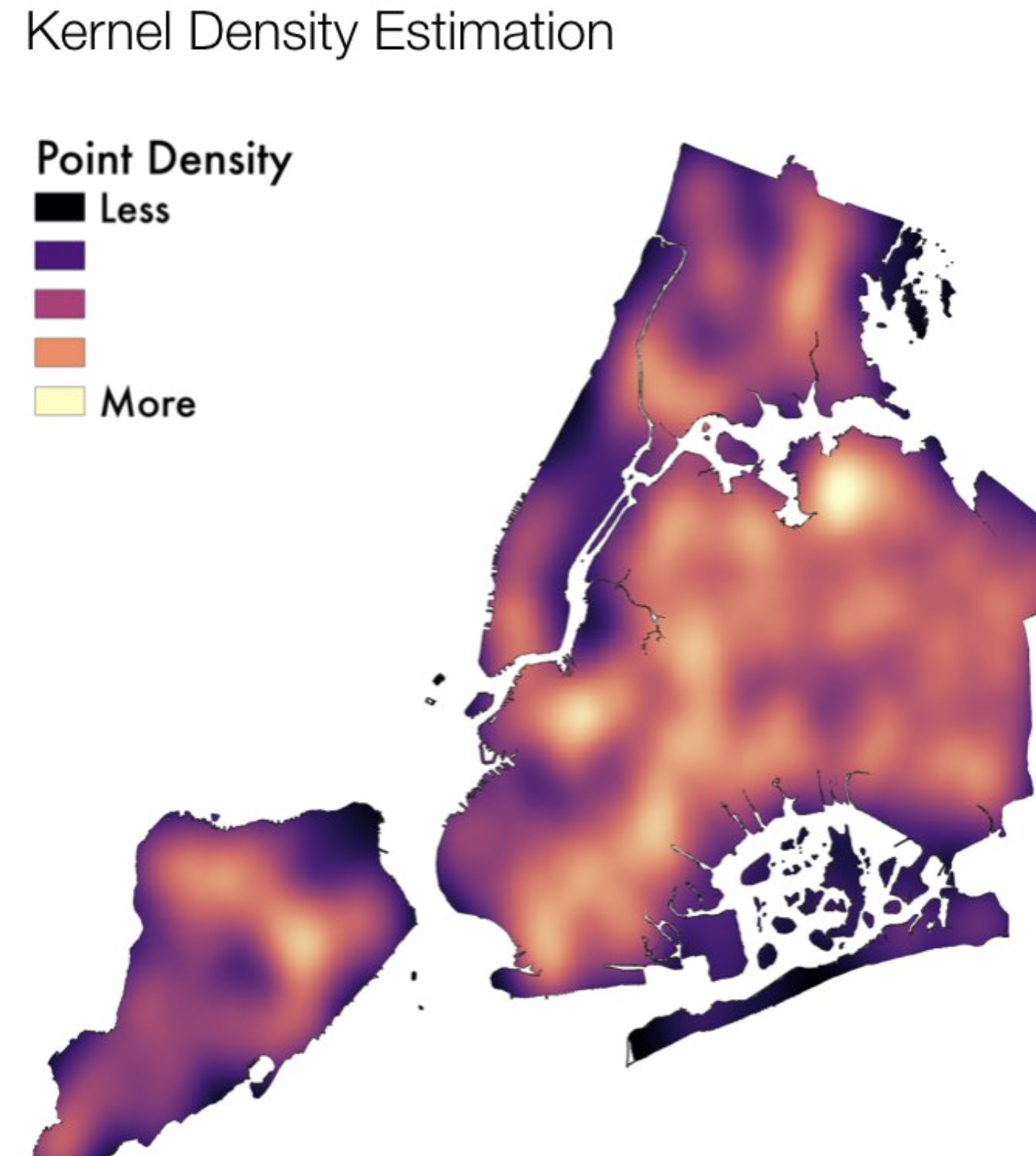
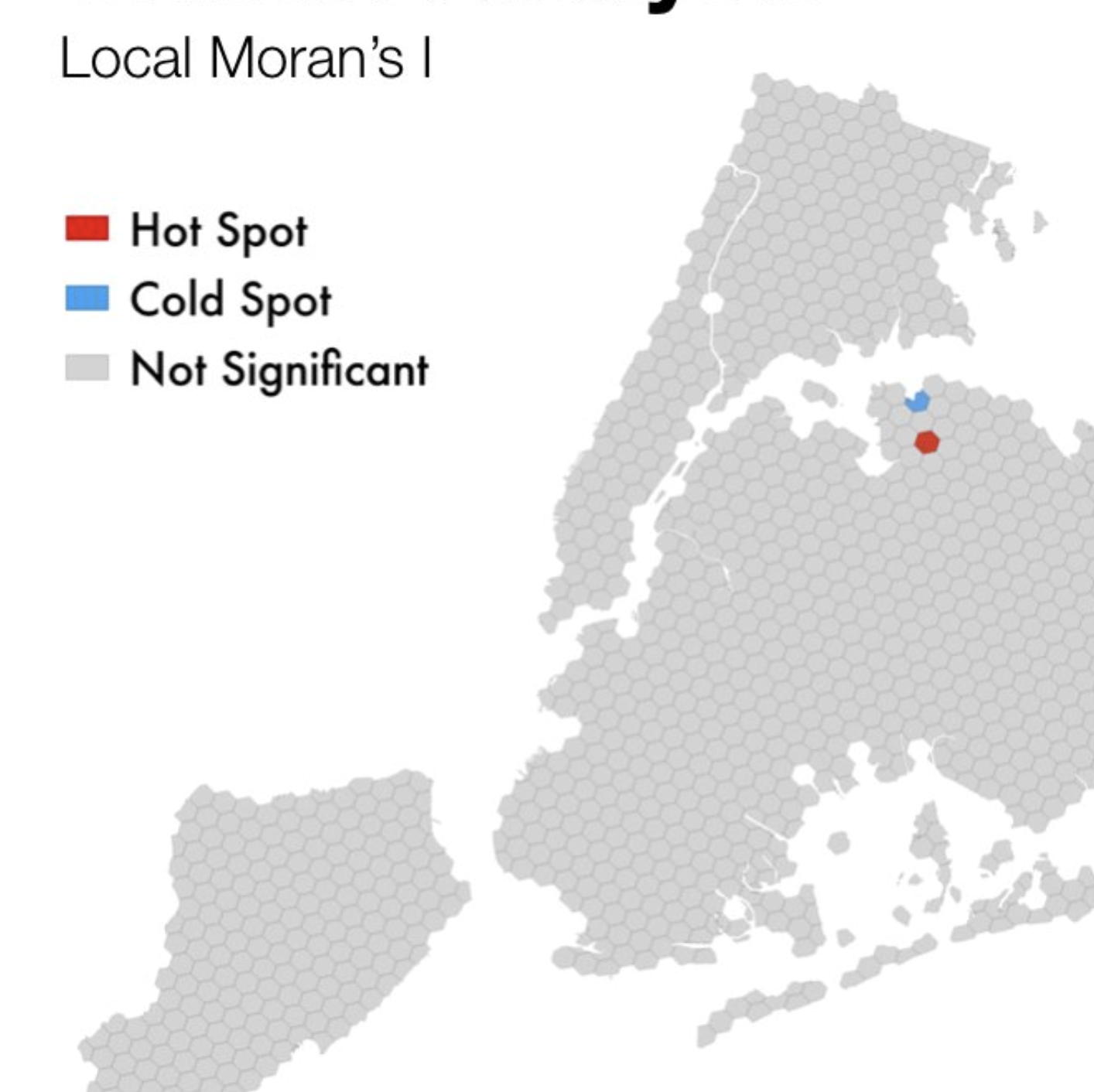
Tree data
nytrees_example
Simple feature collection with 683683 features and 5 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: 913349.3 ymin: 120973.8 xmax: 1067248 ymax: 271894.1
Projected CRS: NAD83 / New York Long Island (ftUS)
# A tibble: 683,683 × 6
nta_code nta_name spc_common latitude longitude geometry
<chr> <chr> <chr> <chr> <chr> <POINT [US_survey_foot]>
1 QN17 Forest Hills red maple 40.7230… -73.8442… (1027431 202756.8)
2 QN49 Whitestone pin oak 40.7941… -73.8186… (1034456 228644.8)
3 BK90 East Willia… honeylocu… 40.7175… -73.9366… (1001823 200716.9)
4 BK90 East Willia… honeylocu… 40.7135… -73.9344… (1002420 199244.3)
5 BK37 Park Slope-… American … 40.6667… -73.9759… (990913.8 182202.4)
6 MN14 Lincoln Squ… honeylocu… 40.7700… -73.9849… (988418.7 219825.5)
7 MN14 Lincoln Squ… honeylocu… 40.7702… -73.9853… (988311.2 219885.3)
8 MN15 Clinton American … 40.7627… -73.9872… (987769.1 217157.9)
9 SI14 Grasmere-Ar… honeylocu… 40.5965… -74.0762… (963073.2 156635.6)
10 BK26 Gravesend London pl… 40.5863… -73.9697… (992653.7 152903.6)
# ℹ 683,673 more rows
Simple feature collection with 683683 features and 8 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: 913349.3 ymin: 120973.8 xmax: 1067248 ymax: 271894.1
Projected CRS: NAD83 / New York Long Island (ftUS)
# A tibble: 683,683 × 9
nta_code nta_code20 nta_name20 nta_name spc_common latitude longitude
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 QN17 QN0602 Forest Hills Forest … red maple 40.7230… -73.8442…
2 QN49 QN0702 Whitestone-Beechh… Whitest… pin oak 40.7941… -73.8186…
3 BK90 BK0104 East Williamsburg East Wi… honeylocu… 40.7175… -73.9366…
4 BK90 BK0104 East Williamsburg East Wi… honeylocu… 40.7135… -73.9344…
5 BK37 BK0602 Park Slope Park Sl… American … 40.6667… -73.9759…
6 MN14 MN0701 Upper West Side-L… Lincoln… honeylocu… 40.7700… -73.9849…
7 MN14 MN0701 Upper West Side-L… Lincoln… honeylocu… 40.7702… -73.9853…
8 MN15 MN0402 Hell's Kitchen Clinton American … 40.7627… -73.9872…
9 SI14 SI0201 Grasmere-Arrochar… Grasmer… honeylocu… 40.5965… -74.0762…
10 BK26 BK1301 Gravesend (South) Gravese… London pl… 40.5863… -73.9697…
# ℹ 683,673 more rows
# ℹ 2 more variables: geometry <POINT [US_survey_foot]>, intersection <int>
Example 2: nycdogs again
The nycdogs package
library(nycdogs)nyc_license
# A tibble: 493,072 × 9
animal_name animal_gender animal_birth_year breed_rc borough zip_code
<chr> <chr> <dbl> <chr> <chr> <int>
1 Paige F 2014 Pit Bull (or Mi… Manhat… 10035
2 Yogi M 2010 Boxer Bronx 10465
3 Ali M 2014 Basenji Manhat… 10013
4 Queen F 2013 Akita Crossbreed Manhat… 10013
5 Lola F 2009 Maltese Manhat… 10028
6 Ian M 2006 Unknown Manhat… 10013
7 Buddy M 2008 Unknown Manhat… 10025
8 Chewbacca F 2012 Labrador (or Cr… Manhat… 10013
9 Heidi-Bo F 2007 Dachshund Smoot… Brookl… 11215
10 Massimo M 2009 Bull Dog, French Brookl… 11201
# ℹ 493,062 more rows
# ℹ 3 more variables: license_issued_date <date>, license_expired_date <date>,
# extract_year <dbl>
The nycdogs package
The metadata tells you this is not a regular tibble.
nyc_zips
Simple feature collection with 262 features and 11 fields
Geometry type: POLYGON
Dimension: XY
Bounding box: xmin: -74.25576 ymin: 40.49584 xmax: -73.6996 ymax: 40.91517
Geodetic CRS: WGS 84
# A tibble: 262 × 12
objectid zip_code po_name state borough st_fips cty_fips bld_gpostal_code
<int> <int> <chr> <chr> <chr> <chr> <chr> <int>
1 1 11372 Jackson He… NY Queens 36 081 0
2 2 11004 Glen Oaks NY Queens 36 081 0
3 3 11040 New Hyde P… NY Queens 36 081 0
4 4 11426 Bellerose NY Queens 36 081 0
5 5 11365 Fresh Mead… NY Queens 36 081 0
6 6 11373 Elmhurst NY Queens 36 081 0
7 7 11001 Floral Park NY Queens 36 081 0
8 8 11375 Forest Hil… NY Queens 36 081 0
9 9 11427 Queens Vil… NY Queens 36 081 0
10 10 11374 Rego Park NY Queens 36 081 0
# ℹ 252 more rows
# ℹ 4 more variables: shape_leng <dbl>, shape_area <dbl>, x_id <chr>,
# geometry <POLYGON [°]>
The nycdogs package
nyc_zips |>select(objectid:borough)
Simple feature collection with 262 features and 5 fields
Geometry type: POLYGON
Dimension: XY
Bounding box: xmin: -74.25576 ymin: 40.49584 xmax: -73.6996 ymax: 40.91517
Geodetic CRS: WGS 84
# A tibble: 262 × 6
objectid zip_code po_name state borough geometry
<int> <int> <chr> <chr> <chr> <POLYGON [°]>
1 1 11372 Jackson Heights NY Queens ((-73.86942 40.74916, -73.89…
2 2 11004 Glen Oaks NY Queens ((-73.71068 40.75004, -73.70…
3 3 11040 New Hyde Park NY Queens ((-73.70098 40.7389, -73.703…
4 4 11426 Bellerose NY Queens ((-73.7227 40.75373, -73.722…
5 5 11365 Fresh Meadows NY Queens ((-73.81089 40.72717, -73.81…
6 6 11373 Elmhurst NY Queens ((-73.88722 40.72753, -73.88…
7 7 11001 Floral Park NY Queens ((-73.70098 40.7389, -73.699…
8 8 11375 Forest Hills NY Queens ((-73.85625 40.73672, -73.85…
9 9 11427 Queens Village NY Queens ((-73.74169 40.73682, -73.73…
10 10 11374 Rego Park NY Queens ((-73.86451 40.73407, -73.85…
# ℹ 252 more rows
The polygon column is a list of lat/lon points that, when joined, draw the outline of the zip code area. This is much more compact than a big table where every row is a single point.
Let’s make a summary table
nyc_license
# A tibble: 493,072 × 9
animal_name animal_gender animal_birth_year breed_rc borough zip_code
<chr> <chr> <dbl> <chr> <chr> <int>
1 Paige F 2014 Pit Bull (or Mi… Manhat… 10035
2 Yogi M 2010 Boxer Bronx 10465
3 Ali M 2014 Basenji Manhat… 10013
4 Queen F 2013 Akita Crossbreed Manhat… 10013
5 Lola F 2009 Maltese Manhat… 10028
6 Ian M 2006 Unknown Manhat… 10013
7 Buddy M 2008 Unknown Manhat… 10025
8 Chewbacca F 2012 Labrador (or Cr… Manhat… 10013
9 Heidi-Bo F 2007 Dachshund Smoot… Brookl… 11215
10 Massimo M 2009 Bull Dog, French Brookl… 11201
# ℹ 493,062 more rows
# ℹ 3 more variables: license_issued_date <date>, license_expired_date <date>,
# extract_year <dbl>
Let’s make a summary table
nyc_license |>filter(extract_year ==2018)
# A tibble: 117,371 × 9
animal_name animal_gender animal_birth_year breed_rc borough zip_code
<chr> <chr> <dbl> <chr> <chr> <int>
1 Ali M 2014 Basenji Manhat… 10013
2 Ian M 2006 Unknown Manhat… 10013
3 Chewbacca F 2012 Labrador (or Cr… Manhat… 10013
4 Lola F 2006 Miniature Pinsc… Manhat… 10022
5 Lucy F 2014 Dachshund Smoot… Brookl… 11215
6 June F 2010 Cavalier King C… Brookl… 11238
7 Apple M 2013 Havanese Manhat… 10025
8 Muneca F 2013 Beagle Brookl… 11232
9 Benson M 2010 Boxer Brookl… 11209
10 Bigs M 2004 Pit Bull (or Mi… Brookl… 11208
# ℹ 117,361 more rows
# ℹ 3 more variables: license_issued_date <date>, license_expired_date <date>,
# extract_year <dbl>
fb_map |>ggplot(mapping =aes(fill = freq)) +geom_sf(color ="gray30", size =0.1) +scale_fill_viridis_c(option ="A") +labs(fill ="Percent of All French Bulldogs")
First cut at a map
fb_map |>ggplot(mapping =aes(fill = freq)) +geom_sf(color ="gray30", size =0.1) +scale_fill_viridis_c(option ="A") +labs(fill ="Percent of All French Bulldogs") +annotate(geom ="text", x =-74.145+0.029, y =40.82-0.012, label ="New York City's French Bulldogs", size =6) +annotate(geom ="text", x =-74.1468+0.029, y =40.8075-0.012, label ="By Zip Code. Based on Licensing Data", size =5)
First cut at a map
fb_map |>ggplot(mapping =aes(fill = freq)) +geom_sf(color ="gray30", size =0.1) +scale_fill_viridis_c(option ="A") +labs(fill ="Percent of All French Bulldogs") +annotate(geom ="text", x =-74.145+0.029, y =40.82-0.012, label ="New York City's French Bulldogs", size =6) +annotate(geom ="text", x =-74.1468+0.029, y =40.8075-0.012, label ="By Zip Code. Based on Licensing Data", size =5) + kjhslides::kjh_theme_nymap() +guides(fill =guide_legend(title.position ="top", label.position ="bottom",keywidth =1, nrow =1))
Use a different palette
library(colorspace)fb_map |>ggplot(mapping =aes(fill = freq)) +geom_sf(color ="gray30", size =0.1) +scale_fill_continuous_sequential(palette ="Oranges",labels = scales::label_percent()) +labs(fill ="Percent of all French Bulldogs")
Use a different palette
fb_map |>ggplot(mapping =aes(fill = freq)) +geom_sf(color ="gray30", size =0.1) +scale_fill_continuous_sequential(palette ="Oranges",labels = scales::label_percent()) +labs(fill ="Percent of all French Bulldogs") +annotate(geom ="text", x =-74.145+0.029, y =40.82-0.012, label ="New York City's French Bulldogs", size =6) +annotate(geom ="text", x =-74.1468+0.029, y =40.7955, label ="By Zip Code. Based on Licensing Data", size =5) + kjhslides::kjh_theme_nymap() +guides(fill =guide_legend(title.position ="top", label.position ="bottom",keywidth =1, nrow =1))
Keep the Zero-count Zips
nyc_license |>filter(extract_year ==2018) |>group_by(breed_rc, zip_code) |>tally() |>ungroup() |>complete(zip_code, breed_rc, fill =list(n =0)) |># Regroup to get the right denominatorgroup_by(breed_rc) |>mutate(freq = n /sum(n)) |>filter(breed_rc =="French Bulldog") -> nyc_fb2fb_map2 <-left_join(nyc_zips, nyc_fb2, by ="zip_code")
fb_map2 |>ggplot(mapping =aes(fill = freq)) +geom_sf(color ="gray30", size =0.1) +scale_fill_continuous_sequential(palette ="Oranges", labels = scales::label_percent()) +labs(fill ="Percent of all French Bulldogs") +annotate(geom ="text", x =-74.145+0.029, y =40.82-0.012, label ="New York City's French Bulldogs", size =6) +annotate(geom ="text", x =-74.1468+0.029, y =40.7955, label ="By Zip Code. Based on Licensing Data", size =5) + kjhslides::kjh_theme_nymap() +guides(fill =guide_legend(title.position ="top", label.position ="bottom",keywidth =1, nrow =1))